
Dans mon précédent article HTTP/2 en détails, j’avais présenté une vision très haut niveau du fonctionnement des échanges sur le net pour illustrer le principe de base du serveur push.
En réalité, le réseau est généralement plus complexe que ça et ne se limite pas à un client – serveur discutant l’un avec l’autre. Bien souvent, afin de réduire au maximum la latence lors du chargement des ressources, les principaux assets sont « délocalisés » dans un CDN ou Reverse Proxy. Une représentation plus réaliste des flux ressemble donc à ça :
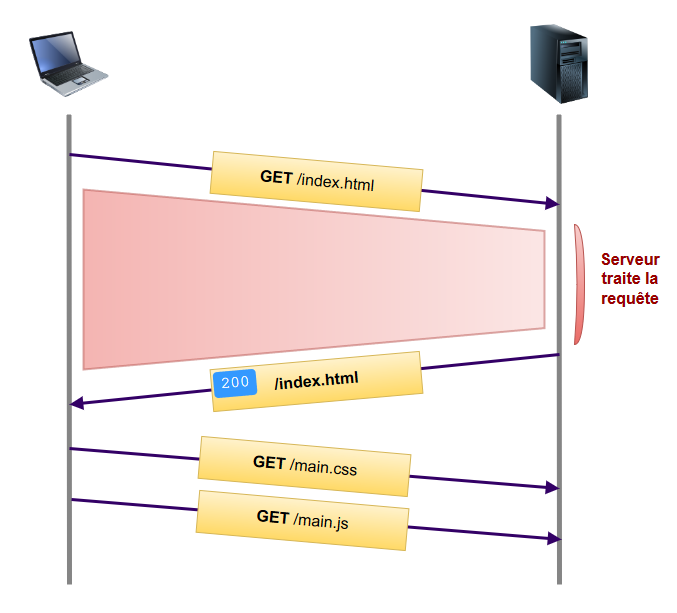
Cet article fait partie de la série HTTP/2, contenant les articles suivants :
- HTTP/2 : introduction
- HTTP/2 : les détails
- HTTP/2 : les anciennes pratiques à éviter maintenant
- HTTP/2 : l’API HTTP Client de Java 11
- HTTP/2 : Push serveur
- HTTP/2 : Push serveur avec Java EE 8
Serveur push, pourquoi faire ?
Sur le schéma ci-dessus, vous vous rendez compte du problème : du temps perdu lors de la requête initiale (en rouge sur le schéma) et des ressources qui ne sont découvertes que lors du parsing du code HTML reçu (la feuille CSS dans notre cas). Pire encore, notre page pourrait comporter des « sous-ressources critiques cachées » et là, en termes de performances, c’est le drame.
Des quoi ?!
Pour comprendre de quoi il s’agit, petit rappel sur comment fonctionne le navigateur :
Afficher un page classique nécessite principalement deux ressources : un page HTML avec laquelle on va construire le DOM et une feuille de style avec laquelle on va construire le CSSOM.
DOM et CSSOM sont ensuite combinés pour former le Render Tree.
A partir du Render Tree le navigateur peut procéder à l’étape de First Paint de la page, étape durant laquelle il effectue la mise en page et peint le contenu.
Puis on passe à l’étape suivante, Text Paint, qui peint les pixels de texte.
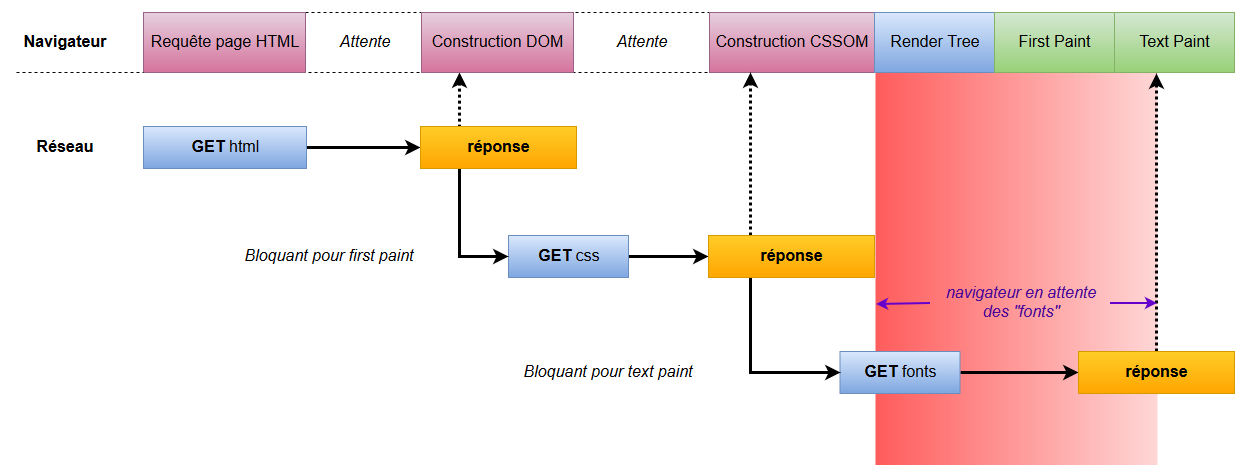
La différence entre le code HTML et CSS c’est que lorsque le navigateur reçoit une page HTML, il peut commencer à construire le DOM au fur et à mesure que les bits arrivent du serveur sans avoir besoin d’attendre que tout le code lui soit parvenu.
En revanche, pour une feuille CSS ce n’est pas possible en raison de la manière dont la cascade fonctionne (on obtiendrait des flashs et « repaint » successifs au niveau de la page). Il faut donc attendre d’avoir reçu le code CSS complet avant de créer le Render Tree et ce n’est qu’à cette étape que le navigateur va récupérer les fonts dont il a besoin pour passer à l’étape de Text Paint.
En effet une feuille CSS peut renseigner une multitude de fonts mais seulement 2 ou 3 seront utiles pour ma page et ça, pour le savoir, le navigateur a besoin du Render Tree.
Voilà pourquoi les fonts sont généralement ce qu’on appelle des « sous-ressources critiques cachées » : « critiques » car nécessaire au rendu initial de ma page et « cachées » car elles ne sont découvertes (et donc récupérées) que très tard dans le processus d’affichage.
Comment faire alors pour indiquer au navigateur que ces ressources sont essentielles et ainsi améliorer les performances d’affichage de ma page ? Le serveur push vient justement répondre à ce genre de besoin.
Optimisation – Level 1 : Preload API
Cela consiste à déclarer les ressources que l’on veut précharger pour la page en cours et uniquement la page en cours (il existe aussi une API prefetch qui permet de charger des ressources utiles pour la future navigation).
Cela peut se présenter sous la forme :
- D’un header :

- D’une balise dans le code HTML ou dans un script JS :
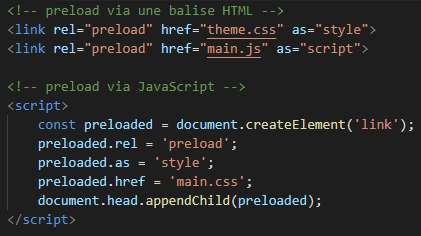
L’attribut as définit le type de ressource, permettant au navigateur d’appliquer la bonne priorité à la ressource. L’attribut crossorigin, quant à lui, est obligatoire pour les fonts (voir documentation MDN). Ainsi notre flux devient :
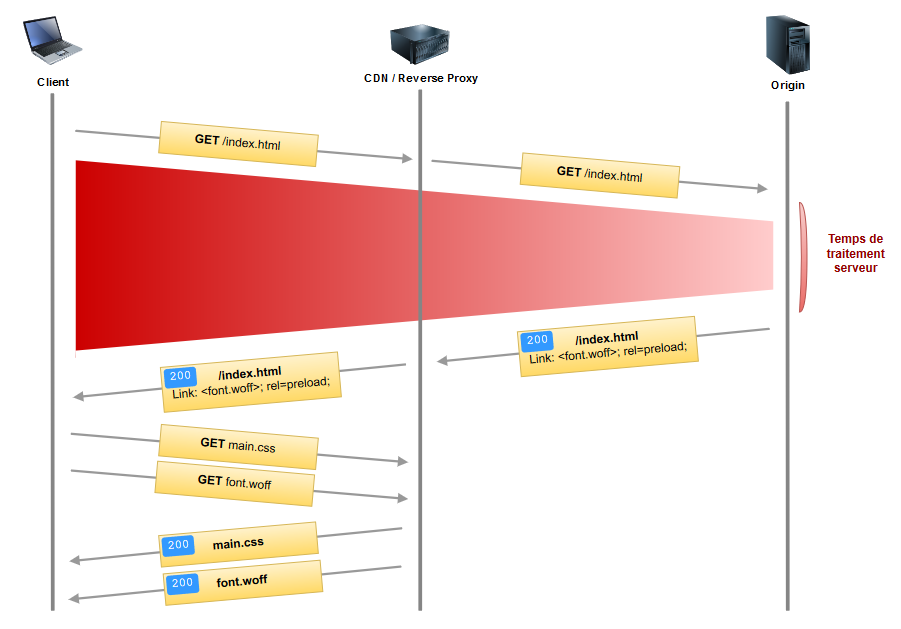
preload permet d’améliorer les performances de chargement d’un site en déclarant les ressources dont on sait que la page va avoir besoin afin que le navigateur les précharge. Dans l’exemple ci-dessus, fonts et feuille CSS sont reçues en même temps par le navigateur au lieu d’avoir à demander les fonts une fois que le parsing du CSS est terminé. On gagne ainsi 1 RTT (comprendre un aller-retour client-serveur correspondant à la requête -> réponse pour les fonts).
A titre d’exemple, Shopify a constaté une amélioration d’environ 50% (1.2s) sur le délai de Text Paint, simplement en ajoutant cette petite ligne de code préchargeant ses fonts. 50% pour quelques balises HTML supplémentaires, je dirais que c’est plutôt rentable.
J’ai fait le test moi-même sur le site sur lequel je travaille :

La première requête utilise preload, les autres non. Sachant que le site n’est pas non plus énorme en termes de ressources (58 requêtes au total, temps de chargement de la page : 850ms) je trouve quand même la différence assez importante.
Une question toutefois : la requête générée par le preload n’arrive-t-elle pas encore trop tard ? On gagne certes du temps par rapport à notre flux de requêtes initial mais on doit quand même attendre de découvrir les balises ou headers preload au moment où on reçoit la page HTML…
De plus, vous l’avez sans doute remarqué, à aucun moment je ne mentionne le serveur push et ça pour la simple et bonne raison que preload n’est pas du serveur push. Cette API est même bien antérieure à HTTP/2 alors pourquoi je vous parle de tout ça ? Et bien en fait c’est directement lié car une manière d’utiliser le serveur push est justement de se baser sur ces headers preload.
Optimisation – Level 2 : Serveur Push
Le CDN/Reverse Proxy se base sur les headers preload pour push les assets vers le client. Démonstration :
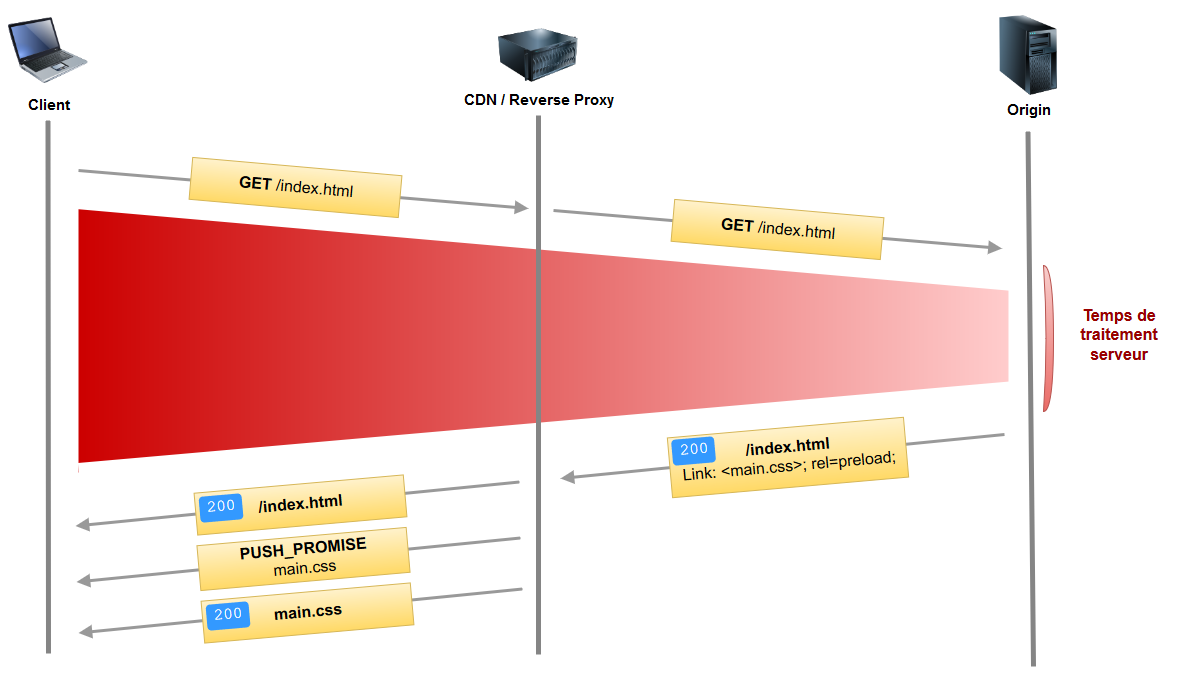
On gagne là aussi 1 RTT : la feuille CSS est directement push par le CDN/Reverse Proxy et reçue par le navigateur en même temps que la page index.html.
Une critique cependant : cela ne résout pas le problème de notre temps d’attente lors de la requête initiale. N’y-a-t-il pas moyen d’utiliser ce temps de latence ?
Optimisation – Level 3 : Async Push
En réalité je ne suis pas sûr que cette technique ait un nom. J’en ai vu plusieurs allant du « hard push » au « async push » et je trouve que celui-ci est assez parlant.
Cela consiste à configurer notre CDN/Reverse Proxy pour qu’en cas de requête, par exemple vers la page index.html, il push automatiquement certains assets.
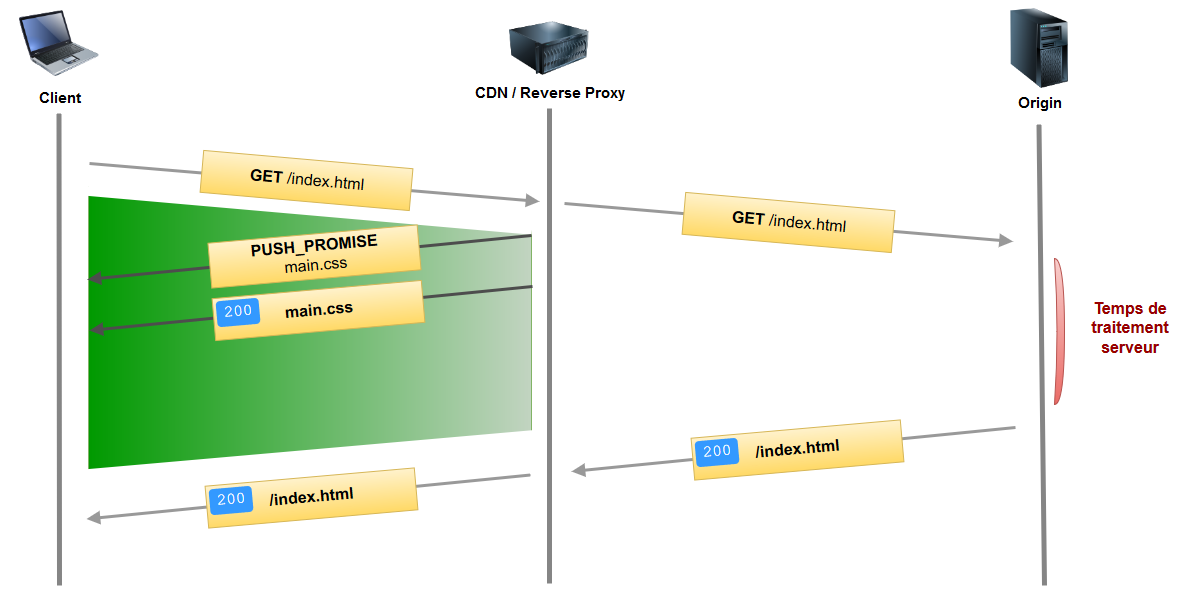
Plus de temps perdu à attendre. Le temps de latence lors de la requête initiale est rentabilisé. Le navigateur aura tout ce dont il a besoin lorsqu’il aura fini de parser le code HTML.
Tout semble parfait désormais, on dirait bien que nous avons réussi à tirer le meilleur parti de ce serveur push. Ce n’était pas si compliqué finalement… Oh ! Attendez, je crois qu’on oublie un détail…
Le cache
C’est là que notre trouble-fête entre en action. Que se passe-t-il en cas de vues répétées sur la page ?
- Avec HTTP 1.1, chaque ressource est récupérée via une connexion TCP propre et mise en cache (cela dépend des « caching headers »). En cas de vues répétées, le navigateur ira la chercher dans le cache, évitant ainsi un nombre important de requêtes.
- Avec HTTP/2 et le serveur push, en cas de vues répétées, et bien on push quand même. Certes on a pas à supporter le coût de l’ouverture de multiples connexions TCP puisque tout se fait au sein de la même connexion, il n’en reste pas moins qu’il s’agit de données superflues entrainant un risque de congestion au niveau du réseau.
Bien sûr le client a la possibilité de décliner un push s’il possède déjà la ressource en cache. Pour cela, à la réception de la frame PUSH_PROMISE émise par le serveur, il doit envoyer une frame RST_STREAM. Cependant, il n’a aucun délai imparti pour faire ça : la frame PUSH_PROMISE est immédiatement suivie des frames DATA constituant la ressource. Une course se lance donc entre la frame RST_STREAM et le transfert de la ressource.
Étant donné que l’on aura tendance à push les ressources critiques pour le rendu de la page et que généralement celles-ci ont une taille relativement faible, c’est malheureusement le RST_STREAM qui va perdre la course et les données seront quand même transférées.
Voila pourquoi le serveur push est bien souvent source de régression plutôt que d’amélioration.
Mais ce n’est pas tout, car on parle souvent de cache navigateur mais il faut savoir que le navigateur possède non pas un unique cache mais plusieurs… De quoi rendre les choses encore plus complexes.
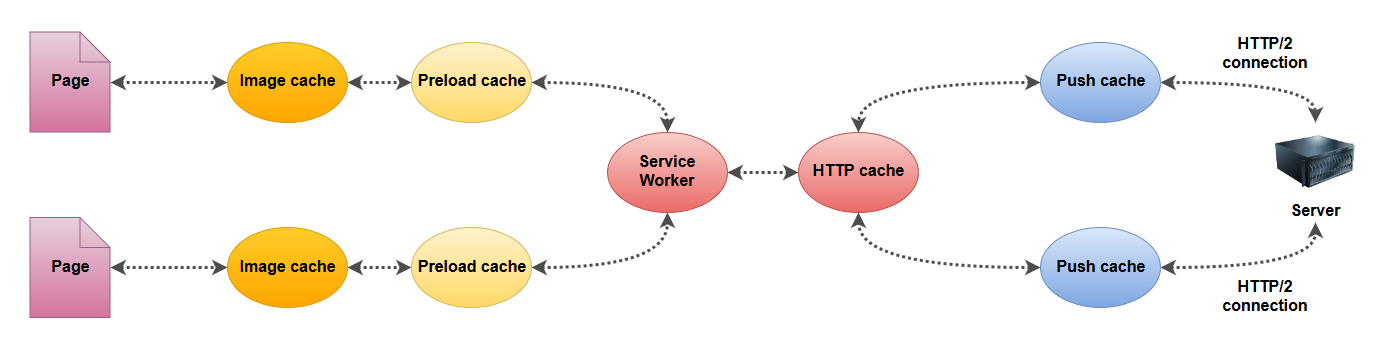
Certains caches sont liés au contexte de la page, d’autres au contexte de la connexion HTTP/2 et d’autres encore sont communs. Qu’est-ce que ça implique pour nous ?
Push cache lié à la connexion
En ce point réside déjà notre première difficulté. Et là vous vous dites : « Quel est le problème ? tu nous as dit qu’en HTTP/2 on utilisant une seule connexion TCP !? »
Et bien c’est vrai… en partie.
Imaginez que vous soyez sur un réseau pas très fiable, dès que vous perdez la connexion vous perdez également le cache…
Autre cas plus complexe : les requêtes avec et sans « credentials »
Les « credentials » sont des données (généralement des headers) que le navigateur envoie avec la requête et qui identifie l’utilisateur (cookies, basic auth, certificats, …).
La plupart des requêtes sont en mode « credentialed » mais, vous vous en doutez, pas toutes. Les requêtes fetch ou celles concernant des fonts ne le sont pas.
Résultat : une même ressource, qu’elle soit push ou récupérée par un fetch, ne partagera pas le même cache.
Push cache en dernière position
Le push cache est le dernier à être vérifié par le navigateur avant d’envoyer la requête. Si, par exemple, vous avez une ressource dans votre cache HTTP, vous pouvez toujours essayer de push la même ressource, plus récente, pour la rafraichir, elle ne sera jamais prise en compte car le navigateur s’arrêtera à celle qu’il trouve dans le cache HTTP.
Ressource utilisable une seule fois
Chaque item dans le push cache est utilisable de manière unique et est retiré du cache après ça (il est toutefois possible qu’il soit ensuite placé dans le cache HTTP, cela dépendra des « caching headers »).
Et enfin, le cache n’est pas standardisé
Il n’y a aucune spécification concernant l’implémentation du cache et la conséquence est que le comportement varie selon les navigateurs.
Cela va de Edge ayant un support pauvre de la fonctionnalité (mais au moins pauvre de manière constante) à Safari qui, lui, a une approche complètement non déterministe (comprendre des fois ça marche, des fois ça marche pas), en passant par Chrome et Firefox qui sont les seuls à assurer un bon support de la fonctionnalité.
Attention « bon support » ne veut pas dire parfait. Certains exemples sont assez croustillants, notamment Firefox qui, lors d’un RST_STREAM (indiquant qu’il a déjà la ressource dans son cache) va « drop » non seulement le stream mais également la ressource dans son cache, le laissant avec … rien du tout ?!!
Si vous souhaitez aller plus loin concernant le support du serveur push sur les différents navigateurs, il y a un excellent article de Jake Archibald qui détaille tout ça.
La seule solution pour palier ces différences d’implémentations serait de faire du « UA sniffing », ce qui revient à appliquer différentes politiques au niveau du serveur en fonction du navigateur (et de sa version) client. ![]()
« Bon c’est bien de lister tout ce qui ne va pas avec le serveur push, mais nous comment on l’utilise nous ? »
A l’heure actuelle, les solutions (simples) ne sont pas très nombreuses et c’est certainement ce qui explique le très faible taux d’adoption de la fonctionnalité.
PRPL Pattern
C’est un pattern développé par Google qui permet une utilisation efficace du serveur push. Toutefois cela nécessitera d’avoir à votre disposition un Service Worker. C’est donc particulièrement adapté aux PWAs qui, Ô surprise, sont aussi développées par Google. ![]()
PRPL signifie :
- Push critical resources for the initial URL route
- Render initial route
- Pre-cache remaining route
- Lazy-load and create remaining routes on demand
L’idée consiste à push uniquement les ressources critiques pour le rendu initial de la page. Puis on utilise le Service Worker pour pré-cache le reste des ressources et on ne charge les pages qu’à la demande de l’utilisateur.
On remarque quand même une utilisation pour le moins prudente du serveur push qui ne va vraiment être utilisé qu’à l’initialisation de l’application et pour le moins de ressources possibles. Le reste est ensuite géré par le Service Worker.
Devant toutes ces difficultés, on peut et on doit se demander : est-ce que le jeu en vaut la chandelle, est-ce que le gain attendu vaut toute cette complexité supplémentaire ? A cette question je n’ai pas de réponse, si ce n’est vous rappeler que la fonctionnalité est encore en pleine évolution et que des améliorations sont à prévoir.
Le Futur
Tout le problème du serveur push réside dans le fait que le serveur ne sait pas ce que le client a dans son cache et va donc systématiquement push toutes les ressources.
Comment pourrait-on faire en sorte que le serveur ne push que le nécessaire ?
Cache Digest
Comment ça marche ? Le client transmet à chaque requête une frame de type CACHE_DIGEST indiquant au serveur le contenu du cache navigateur. Le serveur, auquel on va donc devoir rajouter une couche de logique pour gérer ce CACHE_DIGEST, peut ainsi sélectionner uniquement les ressources pertinentes pour les push vers le client.
La spécification en est actuellement au stade expérimental.
Toutefois un certain nombre de critiques s’élèvent déjà concernant la complexité de ce principe et surtout sur le fait que cela revient à gérer un « state » au niveau de la connexion dans un protocole HTTP résolument « stateless ».
103 Early Hints
Autre spécification au stade expérimental, cela consiste pour le serveur à envoyer, dès la réception de la requête client, une réponse immédiate avec un code 103 indiquant quelles ressources seront nécessaires. Puis, dans un deuxième temps, le serveur enverra la réponse classique 200 contenant les données.
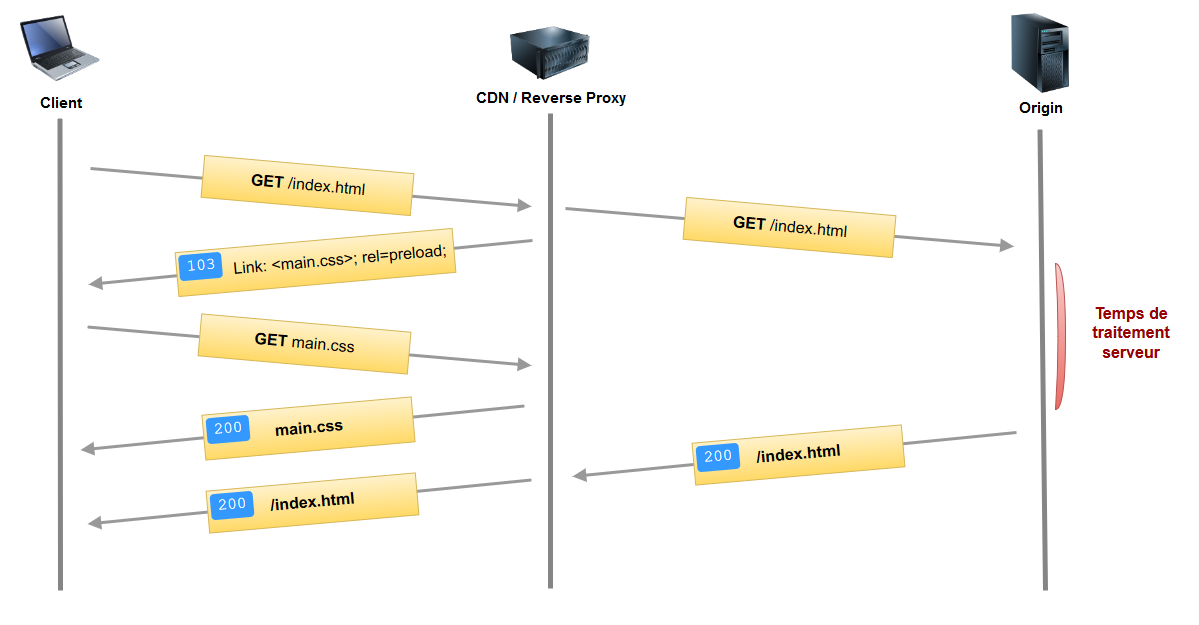
Cela permet, contrairement au cache digest, de laisser la gestion du cache à la charge du navigateur.
A noter que cette fonctionnalité ne fait pas du tout appel au serveur push.
Le fait qu’un grand nombre de proxy ne comprennent pas les réponses de la plage des 100 peut éventuellement poser problème. Toutefois l’utilisation du protocole TLS, qui est pour le moins déjà fortement encouragée, résoudra le souci.
Conclusion
La fonctionnalité de serveur push est encore en pleine évolution mais on peut dire que pour l’instant, à moins d’avoir une PWA, elle est très compliquée à utiliser de manière efficace sans introduire de régression. La mise en place nécessite une bonne compréhension du fonctionnement interne de HTTP/2 mais aussi de la gestion du cache coté navigateur. Nul doute cependant que cette fonctionnalité va s’améliorer dans les années à venir afin de proposer aux développeurs une implémentation plus viable.
Personnellement, même si ce n’est pas lié au serveur push, j’aime beaucoup l’idée du « 103 Early Hints » qui est, je trouve, simple et élégante. A voir si cela deviendra le nouveau standard ou si le serveur push parviendra à s’imposer.
Le dernier article de cette série détaillera comment mettre en oeuvre le serveur Push dans l’API Servlet de Java EE 8.