
Dans ce premier article de la série, je vous propose de partir à la découverte des évolutions apportées par HTTP/2.
Cet article fait partie de la série HTTP/2, contenant les articles suivant :
- HTTP/2 : introduction
- HTTP/2 : les détails
- HTTP/2 : les anciennes pratiques à éviter maintenant
- HTTP/2 : l’API HTTP Client de Java 11
- HTTP/2 : Push serveur
- HTTP/2 : Push serveur avec Java EE 8
Tout d’abord, pour nous développeur qu’est-ce que ça change ?
De ce coté là, pas d’inquiétude, HTTP/2 conserve une rétrocompatibilité complète avec HTTP 1.1. Si HTTP/2 n’est pas disponible dans le navigateur du client, le serveur effectuera automatiquement un « fallback » sur HTTP 1.1. Aucun risque donc de rendre votre site inaccessible pour vos utilisateurs si vous décidez de migrer sur HTTP/2.
De plus HTTP/2 conserve l’intégralité de la syntaxe HTTP 1.1 que ce soit les headers, les URI, les méthodes ou encore les codes. La seule chose qui change au final c’est la manière dont la donnée est segmentée et transportée entre le client et le serveur.
Voyons ça plus en détail :
HTTP 1.1 est un protocole au format texte. En analysant le trafic réseau avec un outil comme WireShark, on peut voir que les données transmises sont parfaitement lisibles :
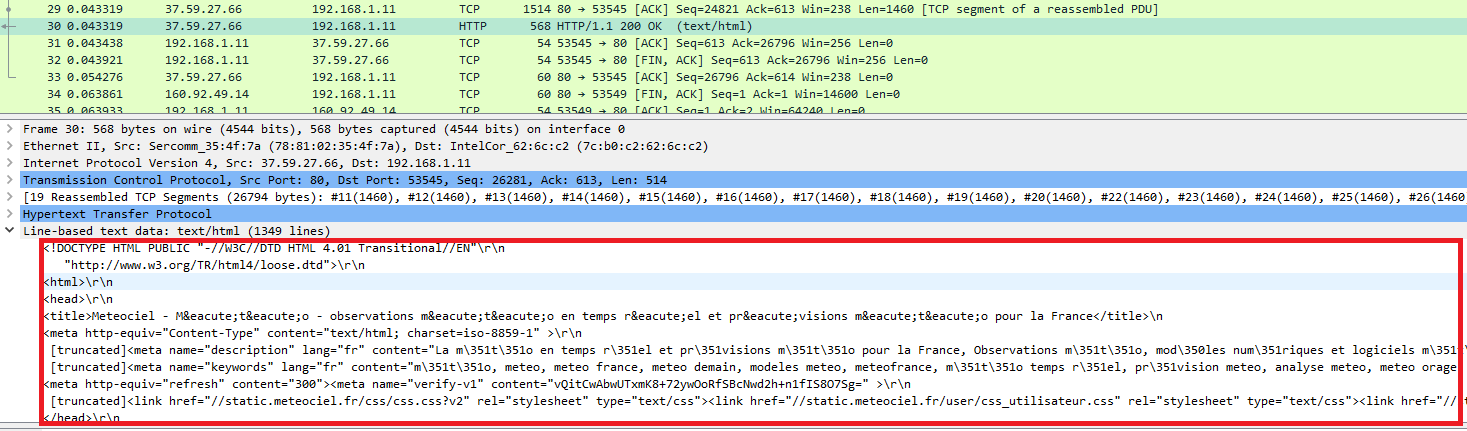
De son coté HTTP/2 est un protocole binaire et la conséquence est que cette fois les données sont illisibles :
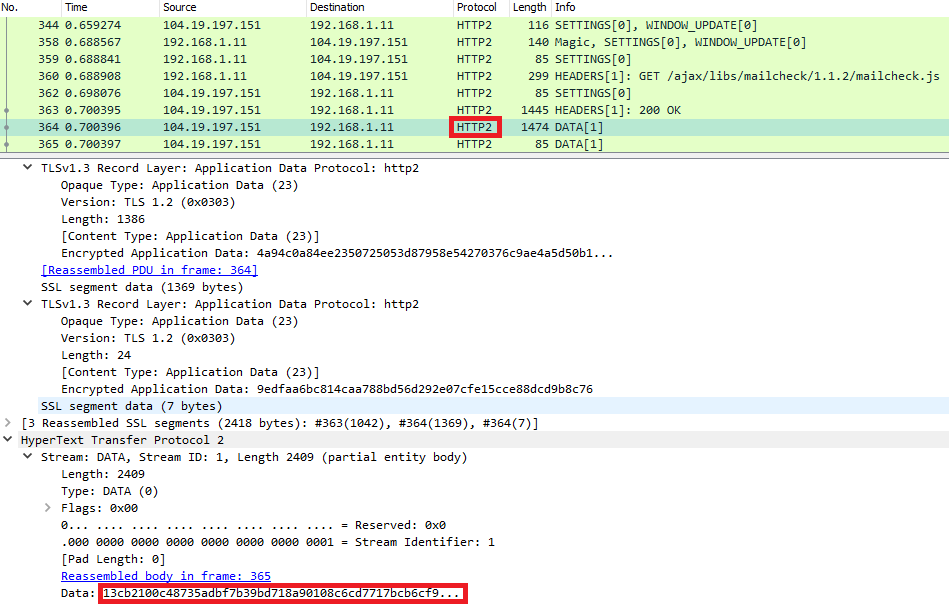
Ce changement de format ne s’est pas fait sans raisons et vous comprendrez par la suite pourquoi cela a de l’importance.
Le multiplexage de flux
C’est certainement l’évolution la plus importante de HTTP/2.
=> En HTTP 1.1 on charge les ressources de manière séquentielle, les unes après les autres. Chaque requête ouvre une connexion TCP pour récupérer une ressource. La requête suivante, elle, doit attendre que la connexion soit fermée pour en ouvrir une nouvelle. C’est ce qu’on appelle le « Head-of-line blocking » (en réalité, les connexions ne sont pas fermées après chaque ressource transférée, elles sont par défaut en mode « keep-alive », c’est à dire réutilisées pour les prochaines requêtes. En revanche, elles ne peuvent bien transférer qu’une seule ressource à la fois).
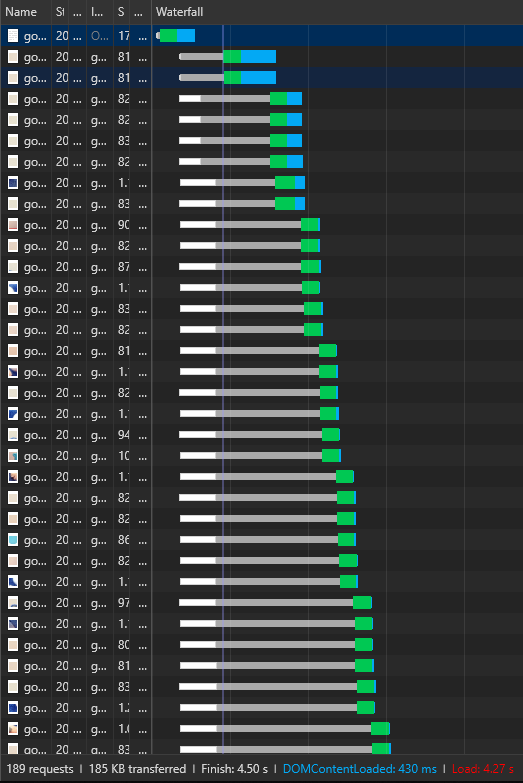
Exemple ci-dessous avec le chargement d’une image divisée en 190 fragments et dont le chargement final prend 4,27s en HTTP 1.1″
Les navigateurs ouvrent en général plusieurs connexions TCP avec un même serveur pour charger des ressources en parallèles mais le nombre de connexions concurrentes vers un même domaine est limité à 6. De plus ouvrir une connexion TCP n’est pas gratuit et prend entre 50 et 120ms.
=> En HTTP /2 on ouvre une seule connexion TCP pour charger toutes les ressources venant de ce domaine, c’est le principe du multiplexage. Cette fois-ci la même image prend 1.24s pour être complètement chargée :

Comment ça marche ?
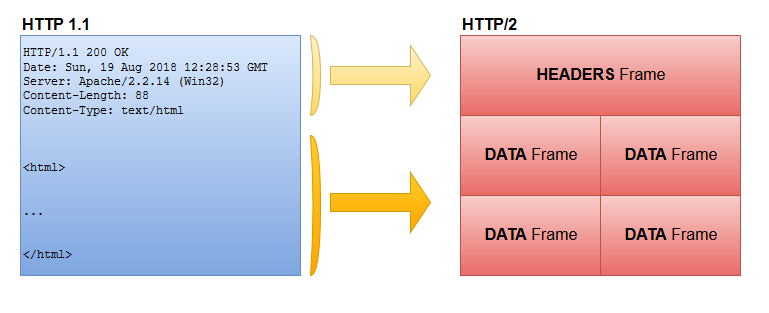
Chaque message HTTP est segmenté en frame (rien à voir avec les frames du layer Datalink du modèle OSI, ici on reste bien au niveau applicatif à l’intérieur du protocole HTTP). L’un des intérêts de l’utilisation d’un protocole binaire comme décrit plus haut est justement de faciliter cette opération de « framing ».
Chaque frame possède un certain nombre de caractéristiques comme la longueur ou encore le type.
Il y a différents types de frame définis dans la spécification HTTP/2 mais les deux principaux sont DATA et HEADERS (si vous avez déjà utilisé le protocole HTTP vous ne devriez pas être dépaysé).
Mais comment, si toutes mes frames passent par mon unique connexion TCP, je fais le tri à l’arrivée pour reconstituer mon message ?
Chaque frame possède en fait un attribut supplémentaire : le stream ID.
Un stream peut être défini comme une séquence indépendante et bidirectionnelle de frames échangée entre un client et un serveur au sein d’une connexion HTTP/2. On peut grosso-modo assimiler un stream à un flux requête + réponse classique en HTTP 1.1.
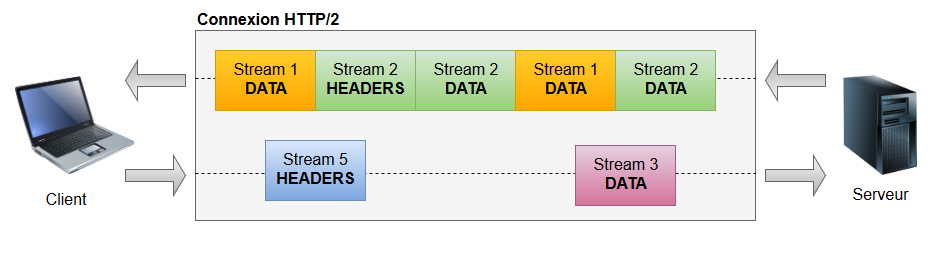
Et là où HTTP/2 innove, c’est qu’une seule connexion TCP peut contenir plusieurs streams ouverts en concurrence. Chaque frame sera raccordée à l’un de ces streams et l’ouverture d’un stream peut se faire aussi bien à l’initiative du client que du serveur.
Qu’est-ce que ça change ?
Cela réduit tout simplement le temps de chargement d’une page en économisant le nombre de connexions TCP ouvertes et en chargeant les ressources en parallèle.
On élimine donc le phénomène de « Head-of-line blocking » (en réalité il est répercuté vers la couche TCP mais cela est hors de la portée de cet article).
De plus, d’une manière plus générale, TCP est optimisé pour des connexions longue durée alors que la plupart des requêtes HTTP sont rapides et éphémères. HTTP/2 permet donc un meilleur usage des connexions TCP réduisant ainsi la charge réseau globale.
Pour aller plus loin : la priorisation de stream
Vous avez décidé de sauter le pas et de migrer tous vos serveurs HTTP vers HTTP/2. Tout se déroule pour le mieux, vous avez vos frames qui transitent dans un ordre aléatoire au sein de la même connexion TCP. Mais là vous analysez votre flux réseau et vous vous dites : « Pourquoi est-ce que cette image qu’on ne voit pas sur la page d’accueil est toujours chargée avant mon image d’entête ?! »
Ne serait-il pas merveilleux de pouvoir dire quelles ressources charger en priorité ?
Eh bien c’est justement ce que permet HTTP/2 en offrant la possibilité d’attribuer à chaque stream un poids et une ou plusieurs dépendances envers d’autres streams.
La combinaison de ces deux attributs permet au client de construire un « arbre de priorité » exprimant comment il préfère recevoir la réponse. Le serveur de son côté peut utiliser cet arbre pour affecter plus ou moins de ressources aux streams en fonction de leur importance. Exemple ci-dessous :
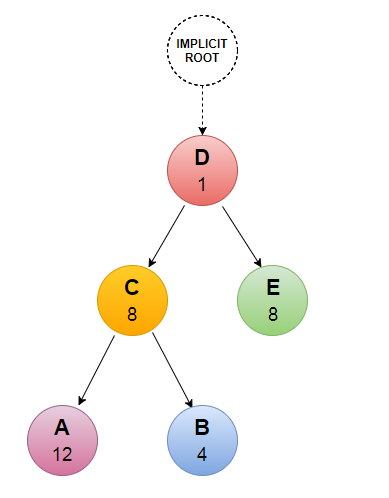
- Etape 1 : La ressource D est la première a être chargée => 100% des ressources serveur sont attribuées à cette tâche.
- Etape 2 : D est chargée. D possède une dépendance vers E et C qui possèdent un attribut poids identique (8) => E et C recevront chacune 50% des ressources serveur.
- Etape 3 : C est chargée. C possède une dépendance vers A et B. A représentant un poids de 75% et B de 25% => A recevra 75% des 50% de C et B 25% des 50% de C.
Attention toutefois, cet arbre de priorité permet uniquement de définir des préférences. Il n’y a aucune garantie que les ressources seront bien traitées dans cet ordre et cela pour la simple et bonne raison qu’on ne veut pas empêcher le serveur de progresser dans le traitement d’une ressource de second ordre si une autre plus importante se retrouve bloquée.
A noter qu’il existe une proposition en cours d’étude par le W3C concernant la priorisation des ressources :
Actuellement le navigateur attribue une importance par défaut à chacune des ressources. Par exemple une feuille CSS dans la balise head sera toujours chargée en priorité sur une feuille JS, une image aura toujours une priorité moindre, etc…
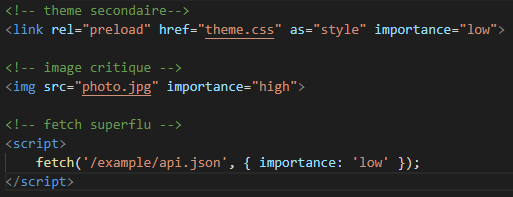
L’idée à l’étude est de pouvoir modifier cette priorité par l’ajout d’un attribut importance directement dans le code HTML comme dans l’exemple suivant :
La compression des headers
Chaque message HTTP transporte un ensemble de headers sous forme de paires clé/valeur qui décrivent la ressource transférée et ses propriétés.
=> En HTTP 1.1 ces headers sont toujours envoyés au format texte, souvent répétés à l’identique. Si leur taille relativement faible semble insignifiante, le phénomène de répétition auquel on peut ajouter la présence de cookies parfois volumineux peut avoir un impact conséquent sur la bande-passante réseau.
=> En HTTP/2, les headers sont compressés en utilisant le format de compression HPACK. Ce dernier a été développé spécialement pour HTTP/2 dans une optique d’efficacité, de simplicité de mise en œuvre et surtout de sécurité.
HPACK se base sur deux principes :
- Toutes les données sont encodées avec un codage de Huffman
- Le client et le serveur doivent maintenir une table indexée des headers précédemment rencontrés. Cela permet lors de requêtes successives de n’envoyer que l’index du header déjà fourni et le client/serveur va reconstituer la liste complète des headers en utilisant la table indexée à sa disposition.
Qu’est-ce que ça change ?
La compression ajoutée à la suppression des headers redondants entre deux requêtes permet de réduire le temps de chargement d’une page, en particulier dans le cas d’un appareil à faible bande passante. Là aussi, le fait que ce soit un protocole binaire rend la compression plus efficace.
Attention, la table indexée est liée à la connexion. Il est impossible que deux connexions partagent la même table et ceci même si elles pointent vers un même domaine.
Pour la petite histoire, la table indexée ne faisait à l’origine que 4 Ko. Certains headers, comme par exemple le header CSP de Twitter, ont une taille supérieure à 4 Ko ce qui écrasait complètement les autres valeurs. Heureusement, aujourd’hui, cette limite a été augmentée à 65 Ko pour les principaux navigateurs et il est de toute façon possible de configurer la connexion (via une frame SETTINGS) pour exclure certains headers de la table.
Serveur Push
C’est une petite révolution dans la manière de communiquer entre le client et le serveur puisque HTTP/2 permet de rompre avec le modèle requête → réponse, avec le client qui doit demander chaque ressource et le serveur qui ne peut que répondre à une requête client. Désormais les ressources peuvent être poussées à l’initiative du serveur alors que le client ne les a pas (encore) demandées.
Dans un premier temps voyons comment une page se charge de manière traditionnelle :
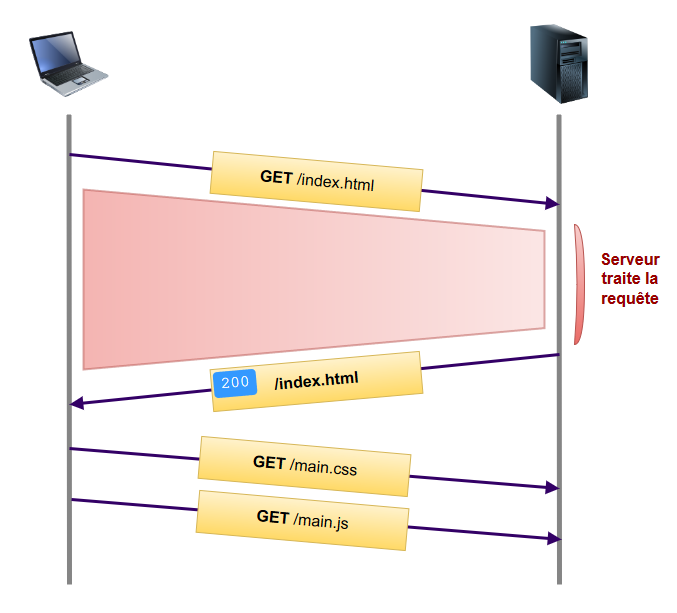
Le client requête la page index.html. Une fois qu’il l’a reçue, il va la parser pour construire le DOM. Dans cette phase de parsing, le navigateur va rencontrer des balises contenant des références vers des fichiers CSS, JavaScript ou encore des images. A chaque fois le client va donc faire une nouvelle requête pour récupérer la ressource en question.
Le problème est ce temps perdu (identifié par la zone rouge dans le schéma ci-dessus) entre le moment ou le client fait la requête initiale et celui où il parse le fichier html et récupère les ressources annexes.
Bien souvent, on sait que pour cette page le client aura également besoin de ce fichier CSS, de ces images, etc… Il faudrait donc un moyen de pouvoir lui transmettre ces ressources directement, sans qu’il n’ait besoin de les découvrir en examinant la page fournie par le serveur. C’est justement ce que permet la fonctionnalité de serveur Push.
Comment ça fonctionne ?
Le serveur va initier un push en créant un nouveau stream et en transmettant au client une frame de type PUSH_PROMISE qui indique ce que le serveur a l’intention d’envoyer. Cette frame contient en fait tous les headers HTTP de la ressource en question. Viennent ensuite les frames DATA classiques.
A la réception de ce PUSH_PROMISE, le client a la possibilité de refuser le stream en transmettant une frame de type RST_STREAM. Cela peut se produire par exemple si le navigateur possède déjà la ressource dans son cache. Voici du coup à quoi ressemble le flux de données :
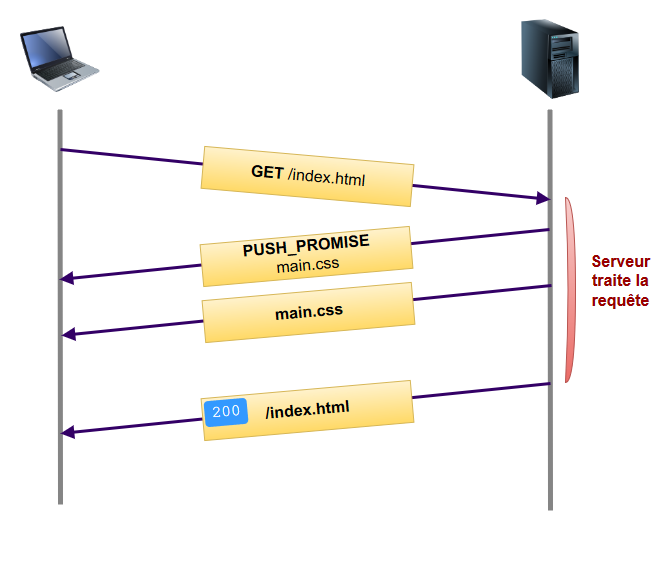
Plus de temps perdu à attendre de recevoir la page initiale, ici les ressources annexes critiques sont poussées directement par le serveur.
Afin d’éviter un article monolithique, je vais m’arrêter là concernant le serveur Push. Cependant, cette fonctionnalité est beaucoup plus complexe que ça, notamment pour être utilisée de manière efficace. C’est d’ailleurs ce qui explique son très faible taux d’adoption aujourd’hui mais il reste encore de nombreuses évolutions en préparation sur ce sujet ![]() )
)
Pour finir
Une dernière amélioration apportée par HTTP/2 concerne la sécurité. En effet, si aucune obligation de chiffrement des flux n’est présente dans la spécification HTTP/2, la plupart des implémentations (Chrome, Firefox, Safari, Edge, etc…) impose une communication en HTTPS pour utiliser HTTP/2, rendant l’utilisation du protocole TLS obligatoire de-facto.
Conclusion
HTTP/2 représente une évolution majeure par rapport à HTTP 1.1, même s’il reste du travail encore aujourd’hui, notamment sur la fonctionnalité de Serveur Push.
Le gain en performance ainsi que le chiffrement permettent non seulement une meilleure expérience utilisateur mais également un meilleur référencement SEO, ces deux critères étant largement pris en compte par les moteurs d’indexation.
De plus son support par un grand nombre de technologies et sa relative facilité de mise en œuvre rendent son adoption très facile. Il n’y a donc plus à hésiter, sautez le pas !!
Pour aller encore plus loin, HTTP/2 n’est même pas encore utilisé partout que déjà la suite se prépare. Si cela vous intéresse je vous invite à jeter un œil au protocole QUIC qui est un protocole lui aussi développé par Google et qui cherche à résoudre le problème que j’ai rapidement évoqué concernant le « Head-of-line blocking » en TCP.
Le prochain article est consacré aux hacks utilisés pour palier à certaines faiblesses d’HTTP/1.1 et qui deviennent obsolètes avec HTTP/2.